
생성적 적대 네트워크 GAN이란?
생성적 적대 신경망(Generative Adversarial Network, GAN)은 새로운 데이터를 생성하는 머신러닝 시스템입니다. 이 인공지능 기술은 실제와 거의 구별할 수 없는 이미지, 텍스트, 음성, 동영상을 만들어내는 능력을 가지고 있습니다.
예를 들어, 페이스북 팀이 개발한 ExGAN은 in-painting GAN의 일종입니다. 아래 이미지에서 첫 번째 열은 원본 이미지, 두 번째 열은 기존 in-painting GAN을 사용해 눈 부위를 생성한 결과이며, 세 번째와 네 번째 열은 페이스북의 ExGAN이 생성한 눈 이미지입니다.
🖌 in-painting GAN이란 사진에서 지워진 부분을 채워 넣는 GAN의 한 종류입니다.

이외에도 GAN은 이미지 분야에서 다양한 용도로 사용됩니다. 저해상도 이미지를 고화질로 변환하거나 흑백 사진을 컬러 이미지로 바꾸는 데 사용되며, 머신러닝 분야에서 훈련 데이터로 사용할 새로운 이미지를 생성하는 데 활용됩니다. 의료 분야에서는 GAN을 통해 구하기 힘든 MRI와 CT 스캔 이미지를 생성하여 머신러닝 모델을 훈련하는 데 쓰이고 있습니다. GAN은 2D 이미지를 사용해 3D 모델을 생성하는 등 다양한 분야에서 그 활용도가 점점 확대되고 있습니다.
GAN의 구성
GAN은 생성기(generator)와 구분자(discriminator)라는 두 개의 신경망으로 구성되어 있습니다.
- 생성기 (Generator): 실제 데이터와 유사한 데이터를 생성하는 방법을 학습합니다. 생성기는 무작위로 입력된 노이즈 (random input)를 기반으로 점차적으로 실제 데이터와 구별할 수 없을 정도로 유사한 데이터를 만들어냅니다.
- 구분자 (Discriminator): 생성기의 가짜 데이터(생성기가 생성한 데이터)와 실제 데이터(훈련 데이터)를 구분하는 방법을 학습합니다. 구분자는 입력된 데이터가 실제 데이터인지 생성된 가짜 데이터인지를 판별하는 역할을 합니다.

생성기와 구분자는 서로 경쟁하면서 점점 더 정교한 데이터를 생성하고 구분할 수 있게 되며, 이 과정에서 GAN의 성능이 향상됩니다.
Adversarial 대립 관계에 있는, 적대적인
GAN의 'A'는 'adversarial(대립적인)'을 의미하며, 이는 두 신경망이 경쟁하며 학습하는 방식을 표현합니다. 생성기의 목표는 구분자를 속여 최대한 그럴싸한 데이터를 생성하는 것이며, 구분자의 목표는 진짜와 가짜 데이터를 정확하게 분류하는 것입니다.
이 관계는 흔히 실제 지폐와 최대한 비슷한 지폐를 생성하는 위조지폐범 🦹🏻 (generator)과 진짜와 위조지폐를 잘 판별해야 하는 경찰 👮🏻(discriminator)로 비유됩니다.
GAN의 훈련 방식
GAN의 훈련 과정은 생성기와 구분자가 서로 경쟁하면서 점점 더 정교한 데이터를 생성하고 구분할 수 있게 되는 반복적인 과정입니다. 이 훈련 과정에서는 두 신경망이 서로를 향상시키기 위해 번갈아 가며 학습합니다.


훈련 과정:
- STEP 1: 👮🏻 구분자 훈련: 구분자는 생성기에서 생성한 가짜 데이터와 실제 데이터를 함께 입력받아, 이들이 진짜인지 가짜인지를 구분하는 방법을 학습합니다. 이 과정에서 구분자는 실제 데이터에는 '진짜' 라벨을, 생성된 데이터에는 '가짜' 라벨을 할당하며, 이 둘을 정확하게 구분하는 능력을 키웁니다 (이진 분류 Binary classification)

- STEP 2: 🦹🏻 생성기 훈련: 생성기의 목표는 구분자가 가짜 데이터를 진짜로 오인하도록 속이는 것이 목표입니다. 생성기 훈련 시에는 구분자가 고정되어 있고, 생성기가 생성한 데이터를 구분자가 진짜로 분류할 확률을 최대화하는 방향으로 학습합니다.


이 두 단계가 번갈아 가며 반복되면서 생성기와 구분자는 서로를 향상시킵니다. 초기에는 생성기의 데이터가 구분자에게 쉽게 판별되지만, 반복적인 학습 과정을 통해 생성기는 점점 더 실제와 유사한 데이터를 생성하게 되고, 구분자는 점점 더 정교하게 진짜와 가짜를 구분할 수 있게 됩니다. 이 경쟁적인 훈련 과정은 GAN의 성능을 극대화하며, 결과적으로 매우 현실적인 데이터를 생성할 수 있게 합니다.
손실 함수:
- 👮🏻 구분자 손실 함수: 구분자의 손실 함수는 실제 데이터에 대해 '진짜'로 분류할 확률과 가짜 데이터에 대해 '가짜'로 분류할 확률을 최대화하는 방향으로 정의됩니다. 이를 통해 구분자는 점점 더 정확하게 진짜와 가짜를 구분할 수 있게 됩니다.
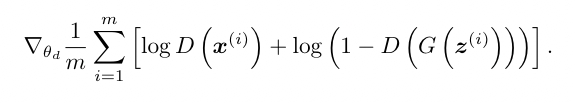
여기서 D(x)는 실제 데이터 x에 대한 구분자의 예측, D(G(z))는 생성된 데이터 G(z)에 대한 구분자의 예측입니다.
- 🦹🏻 생성기 손실 함수: 생성기의 손실 함수는 구분자가 생성된 데이터를 '진짜'로 분류할 확률을 최대화하는 방향으로 정의됩니다. 생성기는 구분자를 속이기 위해 가능한 한 실제 데이터와 유사한 데이터를 생성하는 방법을 학습합니다.

여기서 G(z)는 생성기가 무작위 노이즈 z로부터 생성한 데이터입니다.
GAN은 이미지 생성, 데이터 증강, 이미지 간 변환, 초해상도, 텍스트에서 이미지 합성 등 다양한 분야에서 활용되고 있습니다. 더 자세한 내용은 GAN 모델을 발표한 논문을 읽어보시는 걸 추천드립니다. 이 글이 GAN의 이해와 활용에 도움이 되었기를 바랍니다.
'ᐧ༚̮ᐧ Data Science | AI > 머신러닝 및 딥러닝' 카테고리의 다른 글
| 미 증시를 흔든 중국 AI 딥시크 DeepSeek란? (3) | 2025.01.28 |
|---|---|
| [GenAI #1] 생성형 인공지능 (Generative AI)이란? (29) | 2024.11.18 |
| 머신러닝/딥러닝 논문 읽는 방법 (앤드류 응 교수님법) (0) | 2024.06.21 |
| [머신러닝/딥러닝] Foundation Model이란? (1) | 2024.05.28 |
| AI/머신러닝 논문 사이트 추천 (1) | 2023.02.23 |