
코사인 유사도란?
코사인 유사도는 두 벡터가 얼마나 유사한지를 측정하는 방법을 제공합니다. 이때 벡터의 크기는 결과에 영향을 미치지 않습니다.
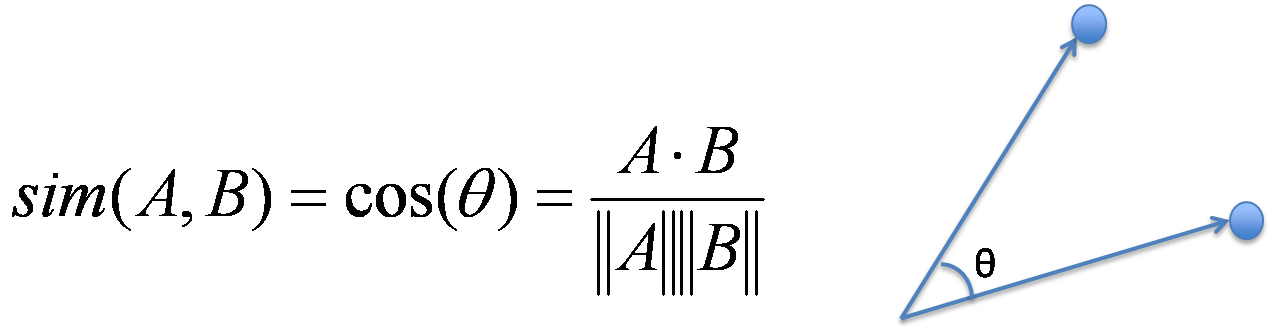
예를 들어, 2차원 공간에서 두 벡터를 고려할 때, 코사인 유사도는 이 벡터들 사이의 각도에 대한 코사인 값을 계산합니다. 이 값은 -1에서 1 사이에 위치하며 다음과 같은 의미를 가집니다:
- 값이 1이면 두 벡터가 동일함을 나타냅니다. (각도 = 0˚)
- 값이 0이면 두 벡터가 완전히 직교함을 나타냅니다. (각도 = 90˚)
- 값이 -1이면 두 벡터가 정반대임을 나타냅니다. (각도 = 180˚)

코사인 유사도는 두 벡터 간의 유사성을 측정하기 때문에 다양한 딥러닝 분야에서 널리 활용됩니다. 예를 들어, 자연어 처리(NLP)에서는 단어 임베딩의 유사성을 계산하여 의미가 비슷한 단어를 식별할 수 있습니다. 이를 통해 문장의 의미를 더 잘 이해하고, 유사한 문장이나 문서 간의 관계를 분석할 수 있습니다.
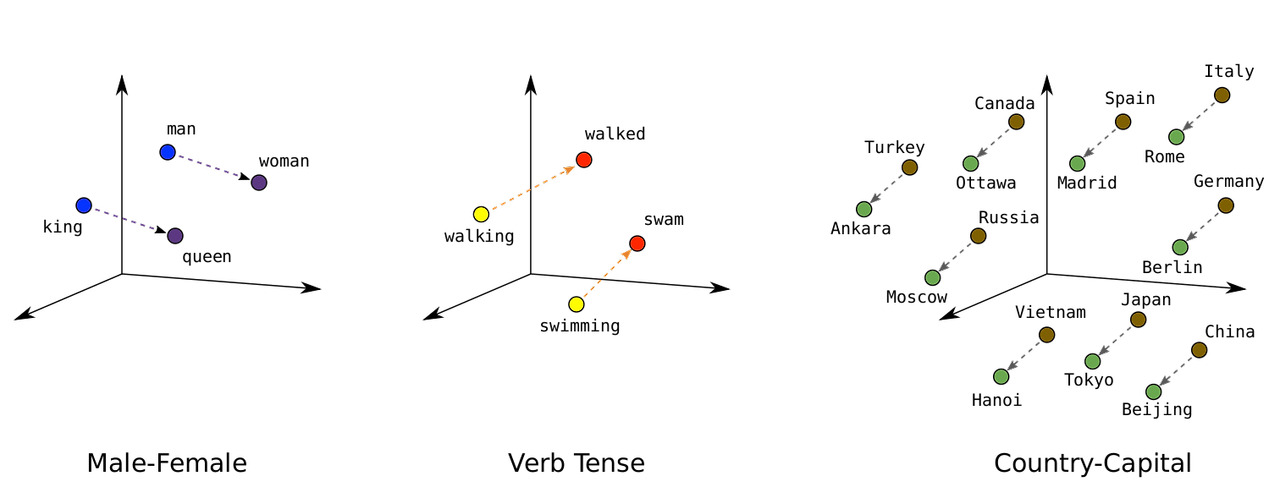
또한, 이미지 인식 분야에서는 이미지 임베딩 간의 유사도를 비교하여 비슷한 이미지를 검색하거나 분류하는 데 사용됩니다. 이는 대규모 이미지 데이터베이스에서 효율적으로 유사한 이미지를 찾는 데 매우 유용합니다.
추천 시스템에서는 사용자와 항목 간의 유사성을 측정하여 개인화된 추천을 제공합니다. 예를 들어, 사용자가 선호하는 영화나 상품과 유사한 항목을 추천함으로써 사용자 경험을 크게 향상시킬 수 있습니다. 코사인 유사도는 이러한 다양한 분야에서 데이터의 내재된 관계를 파악하고, 보다 정교하고 맞춤형의 솔루션을 제공하는 데 중요한 도구입니다.
코사인 유사도 예제
친구 철수와 영희가 각각 5점 만점 영화 평점을 남겼다고 가정해 보겠습니다. 세 영화에 대한 평가 점수는 다음과 같습니다.
- 철수: [4, 5, 2]
- 영희: [4, 4, 3]
이들의 영화 취향이 얼마나 비슷한지 알아보기 위해 코사인 유사도를 계산해 보겠습니다.
1. 내적 계산: 각 평가 점수를 곱하고 합산합니다.
4×4 + 5×4 + 2×3 = 16 + 20 + 6 = 42
2. 크기 계산: 각 평가 벡터의 길이를 계산합니다.
∥철수∥= √(4^2 + 5^2 + 2^2) = √(45) ≈ 6.7
∥영희∥= √(4^2 + 4^2 + 3^2) = √(41) ≈ 6.4
3. 코사인 유사도 계산: 공식을 사용해 코사인 유사도를 계산합니다.
코사인 유사도 = 42 / (6.7 × 6.4) ≈ 0.98
코사인 유사도 0.98은 철수와 영희의 영화 취향이 매우 유사하다는 것을 의미합니다!
딥러닝에서 코사인 유사도의 사용
NLP 예제: 텍스트 비교
두 문장의 유사도를 확인하고 싶다고 가정해 보겠습니다. 각 단어는 워드 임베딩(Word2Vec 또는 GloVe와 같은 기술)을 사용하여 벡터로 표현됩니다. 예를 들어, "I love food"과 "I enjoy eating" 두 문장이 있다고 합시다. 각 단어 벡터를 평균내어 각 문장의 벡터를 얻습니다. 이 두 벡터 간의 코사인 유사도를 계산하여 문장이 얼마나 유사한지 알 수 있습니다. 높은 유사도 값은 두 문장이 비슷한 의미를 가진다는 것을 나타냅니다.
다음 코드는 두 문장의 유사도를 구하는 파이썬 코드 예제입니다. 모델을 불러오고, 단어의 벡처를 평균내어 두 문장의 벡터를 생성한 후, 코사인 유사도를 계산합니다. 두 문장의 코사인 유사도는 0.7917155 결과가 출력됩니다.
import gensim.downloader as api
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# Word2Vec 모델 불러오기
model = api.load("glove-wiki-gigaword-50")
# 문장 벡터를 계산하는 함수
def sentence_to_vector(sentence, model):
words = sentence.lower().split()
word_vectors = []
for word in words:
if word in model:
word_vectors.append(model[word])
if len(word_vectors) == 0:
return np.zeros(model.vector_size)
return np.mean(word_vectors, axis=0)
# 코사인 유사도를 계산하는 함수
def cosine_similarity_sentence(sentence1, sentence2, model):
vec1 = sentence_to_vector(sentence1, model)
vec2 = sentence_to_vector(sentence2, model)
return cosine_similarity([vec1], [vec2])[0][0]
# 예제 문장
sentence1 = "I love food"
sentence2 = "I enjoy eating"
# 유사도 계산
similarity = cosine_similarity_sentence(sentence1, sentence2, model)
print(f"Cosine Similarity: {similarity}")
추천 시스템
코사인 유사도는 제품, 영화, 음악 등의 추천 시스템에서 자주 사용됩니다. 예를 들어, 영화 추천 시스템에서 사용자가 특정 영화를 좋아하면, 시스템은 해당 영화와 유사한 영화들을 추천합니다. 이는 사용자가 평가한 영화와 다른 영화들 간의 코사인 유사도를 계산하여 이루어집니다. 높은 유사도 값을 가지는 영화들은 사용자가 즐길 가능성이 높다고 판단되어 추천됩니다.

- 사용자 A가 평가한 영화: [Harry Potter, Shrek, The Dark Knight Rises]
- 각 영화의 특징 벡터를 이용하여 사용자 A의 선호도를 벡터로 표현합니다.
- 새로운 영화들의 특징 벡터와 사용자의 선호도 벡터 간의 코사인 유사도를 계산하여, 높은 유사도를 가지는 영화들을 추천합니다.
'ᐧ༚̮ᐧ Data Science | AI > 통계, 수학' 카테고리의 다른 글
| 데이터 과학자가 알아야 할 수학: 얼마나 알아야 할까? (3) | 2024.11.17 |
|---|---|
| [통계] p값 이해하기 (1) | 2024.11.14 |
| [통계학 with R, Python] t-검정 (t-test) (1) | 2021.09.12 |
| [통계] 결합확률분포 Joint Distributed Random Variables (0) | 2021.06.15 |
| [통계] 확률변수, 확률분포 (1) | 2021.06.12 |